<li><strong>Use <codeclass="python hljs"><spanclass="hljs-string">'<D/DT>.weekday()'</span></code> to get the day of the week (Mon == 0).</strong></li>
<li><strong><codeclass="python hljs"><spanclass="hljs-string">'fold=1'</span></code> means the second pass in case of time jumping back for one hour.</strong></li>
<li><strong><codeclass="python hljs"><spanclass="hljs-string">'<DTa> = resolve_imaginary(<DTa>)'</span></code> fixes DTs that fall into the missing hour.</strong></li>
<li><strong>TD converts and normalizes args to ±days, seconds (< 86,400) and microseconds (< 1M).</strong></li>
</ul>
<div><h3id="now">Now</h3><pre><codeclass="python language-python hljs"><D/DTn> = D/DT.today() <spanclass="hljs-comment"># Current local date or naive datetime.</span>
<DTn> = DT.utcnow() <spanclass="hljs-comment"># Naive datetime from current UTC time.</span>
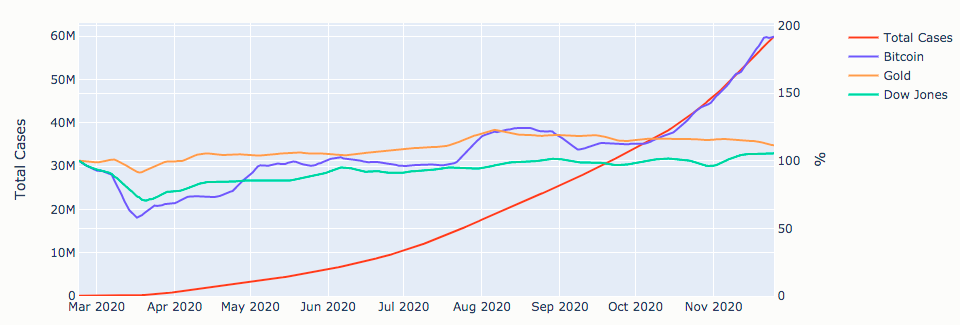
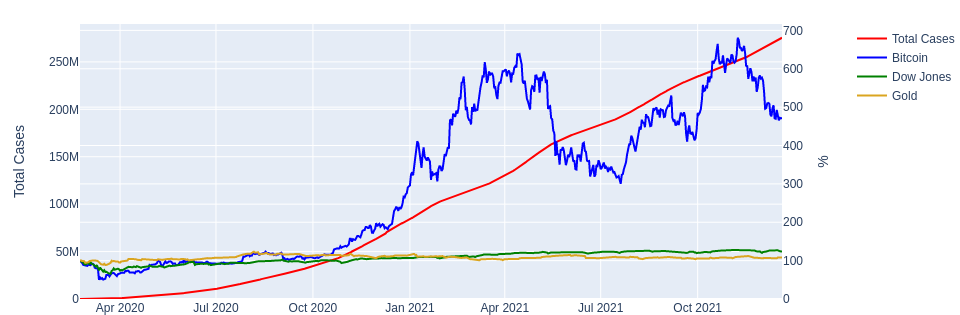
df = pd.concat([bitcoin, gold, dow], axis=<spanclass="hljs-number">1</span>)<spanclass="hljs-comment"># Joins columns on dates.</span>
df = df.sort_index().interpolate()<spanclass="hljs-comment"># Sorts by date and interpolates NaN-s.</span>
df = df.loc[<spanclass="hljs-string">'2020-02-23'</span>:] <spanclass="hljs-comment"># Discards rows before '2020-02-23'.</span>
df = (df / df.iloc[<spanclass="hljs-number">0</span>]) * <spanclass="hljs-number">100</span><spanclass="hljs-comment"># Calculates percentages relative to day 1.</span>
df = df.join(covid) <spanclass="hljs-comment"># Adds column with covid cases.</span>
<spanclass="hljs-keyword">return</span>df.sort_values(df.index[<spanclass="hljs-number">-1</span>], axis=<spanclass="hljs-number">1</span>) <spanclass="hljs-comment"># Sorts columns by last day's value.</span>
{kind=link}
{kind=link}

